
The dynamic performance of characters is an important component of infinite real-time interactive experiences. We care about bringing virtual 3D characters alive, they should exhibit their personalities, tell their stories, express their feelings, and most importantly, respond to our acts naturally and freely. To make this happen, we have been training generative models of 3D motion, and have achieved Real-time Text2motion Generationin September 2024 in our work MotionLCM, and scalable text2motion generation in March 2025 in our work ScaMo. Thanks to these efforts, high-quality motion can be generated to drive virtual characters using text prompts as input. We also introduced TokenHSI (Unified Synthesis of Physical Human-Scene Interactions through Task Tokenization, CVPR2025) to further enable physical interactions of characters in different task performances.
Today, we are excited to present the upgrade of our pipeline. The upgrade is our innovative method for training a small-scale 3D motion generation model from only a single motion data. The overall training process lasts only for a few seconds. And the resulting 3D motion generation model performs conditional motion generation taking target positions of different joints as the condition. To respond to the input condition, the model will perform conditional motion generation in an autoregressive manner while ensuring overall semantics and style of the output stays consistent with the single motion data used for training.
In this way, instead of generating a fixed motion data from text, users can now obtain a 3D motion generation model from text. And different 3D motion generation models obtained in this way provide diverse and rich real-time interactions. Users can control the positions of different joints simply by dragging them or clicking on the screen, and the model immediately generates a corresponding new motion while keeping the semantics and style of the original data. For example, one of these models can help achieve the interaction of users throwing a basketball and the character performs ball-catching action based on the target landing point of the ball. And another one of these models can help achieve the interaction of punching incoming flying enemies, by setting the target position of character’s fists. The interaction between characters, objects, and scenes will become incredibly simple.
Moreover, since these models are small in scale. They can be directly deployed on edge devices like our mobile phones. This means not only we can enjoy interactive motion generation by accessing to large models in the clouds, but also we can have similar functionalities on our devices even without Internet connection.

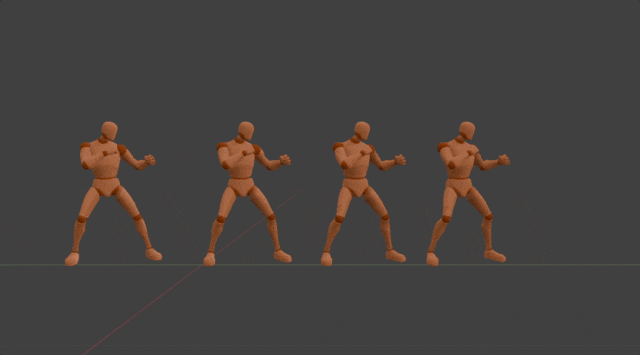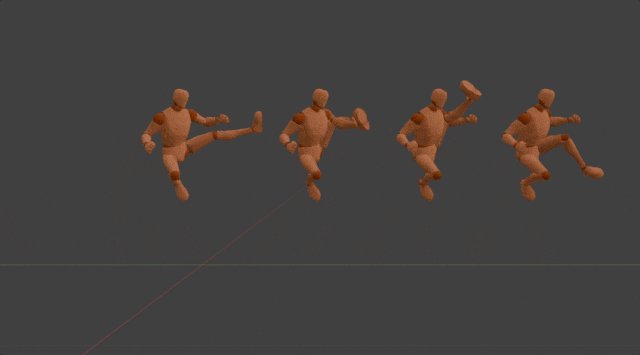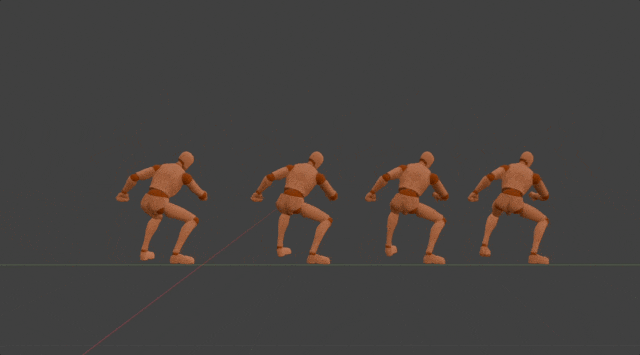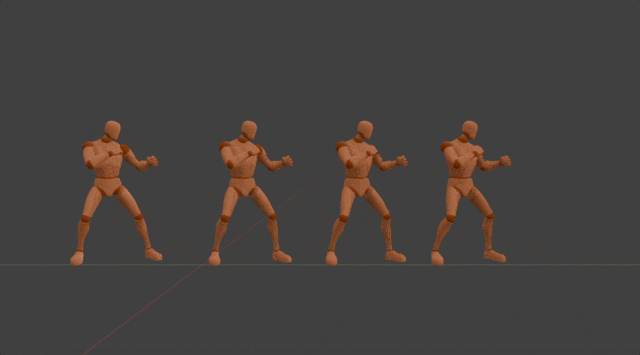
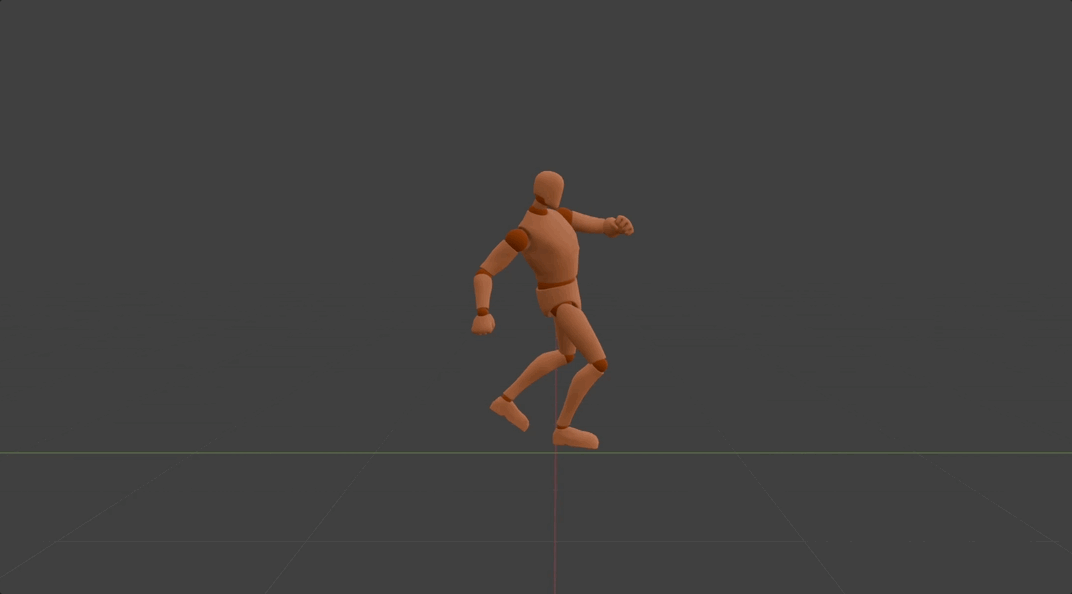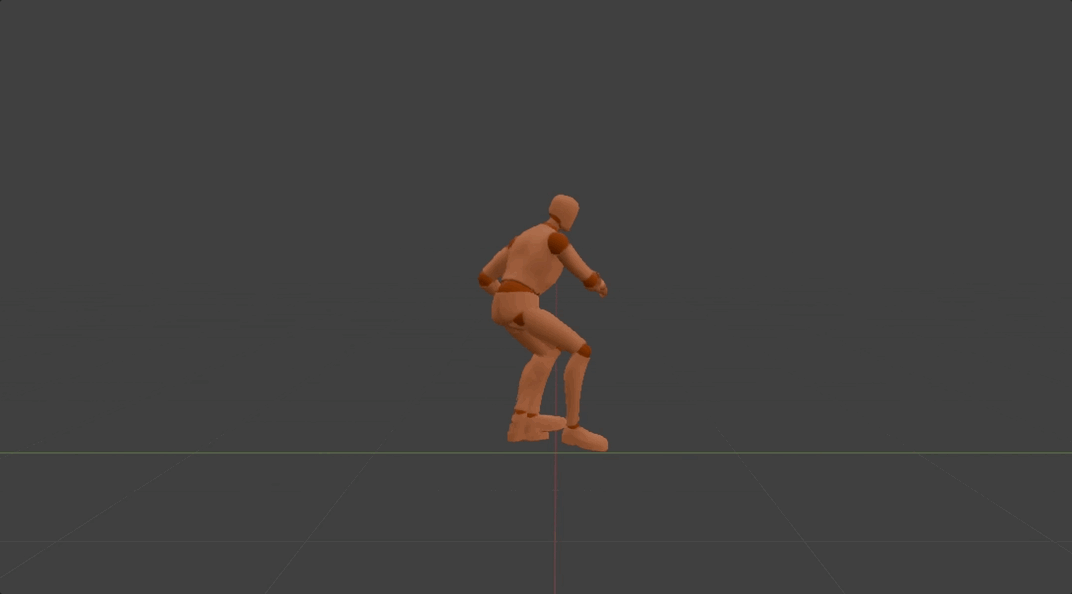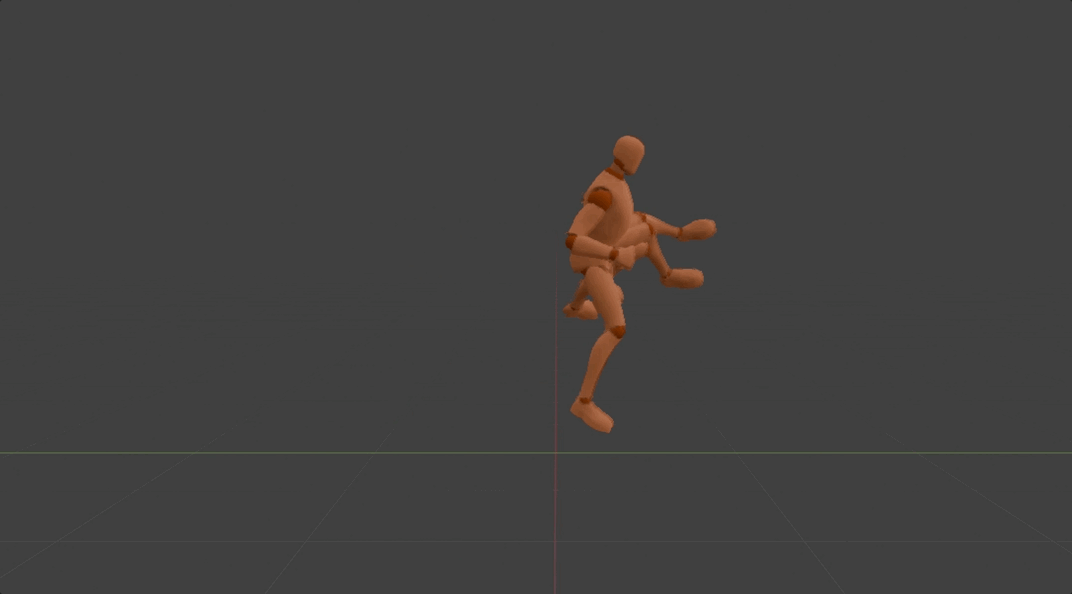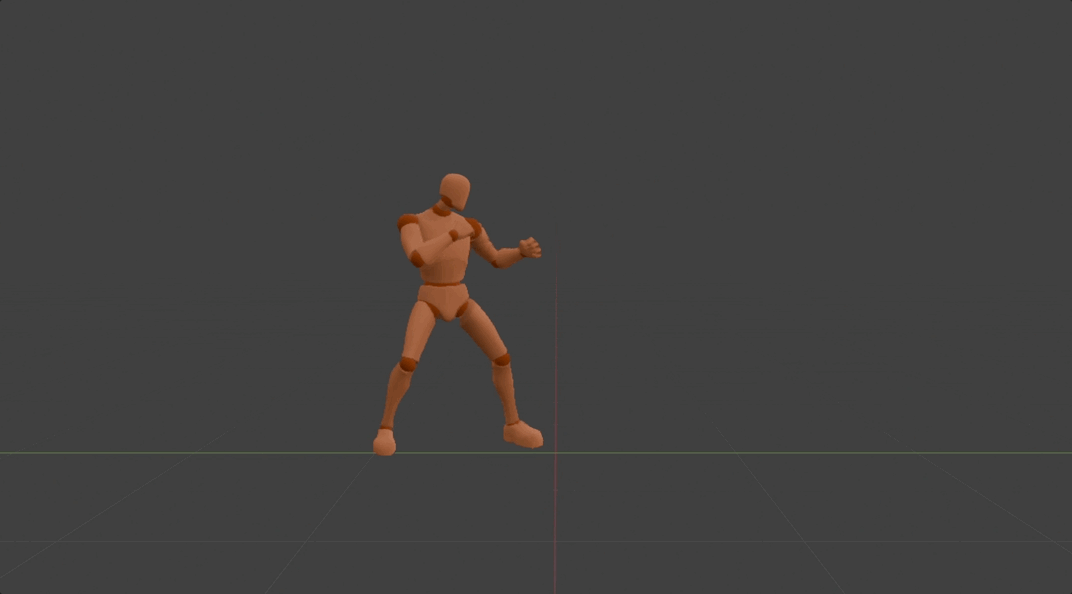
Method
Our method can be categorized into a meta-learning method. Given a single motion as input, it learns to predict a series of intrinsic features from the input, regarding them as the motion DNA. These features grasp detailed semantics of motion movement, like what action this character is doing and how the action is performed at different timesteps. Moreover, these features also capture overall characteristics of the motion, such as its speed, rhythm, and style.
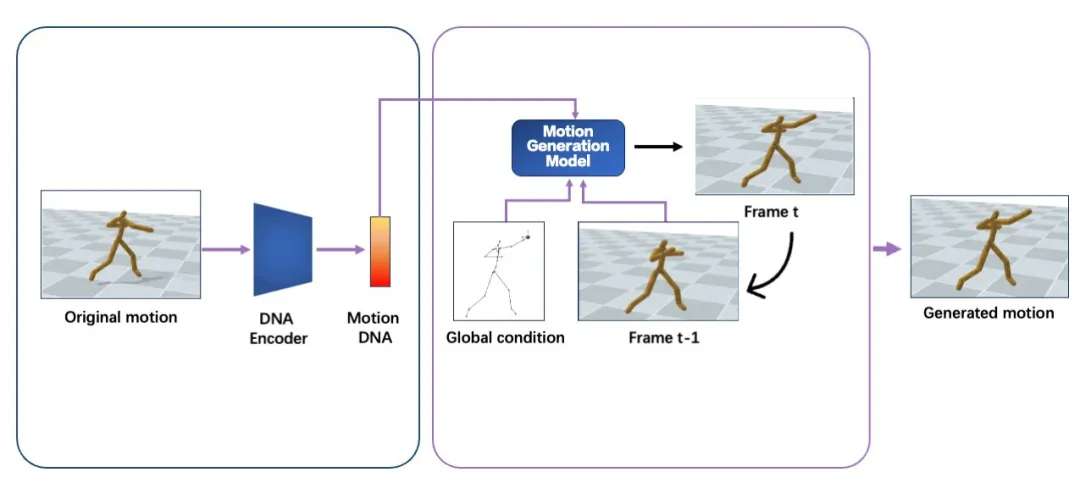
After the motion DNA is extracted,it will be used to determine the parameters of the corresponding 3D motion generation model. In this model, we regard each 3D motion as skeletal movement across discrete timesteps. And skeletal movement is represented as the rotation of each joint relative to its parent joint except for the pelvis joint. This model is designed to generate motion in an auto-regressive manner, where it iteratively predicts skeletal movement at the next timestep, given current movement and the global condition as input. While such an auto-regressive generation process ensures real-time inference speed, 3D positions at specific timestep of specific joints are used as the global condition. This enables versatile useful and fun user-model interactions in a unified format, such as editing motion details by dragging specific joints, clicking on different parts of the opponent to achieve an accurate punch or kick, and dynamically adjusting two hands in order to catch a flying ball. It's worth mentioning all motions generated by the same generation model share the same motion DNA. This effectively ensures the quality of generated motions stays the same as the original one. More importantly, this also preserves the effort used to adapt the original motion into different applications, which means newly generated motions can be seamlessly integrated into previous applications without additional effort.
Looking Ahead
With our method, we can easily obtain a library of real-time 3D motion generation models that have an intuitive and accessible interaction mechanism, an enormous pool of new possibilities emerges and our imagination can be greatly unleashed. Moreover, since models obtained in this way are tiny in their scale and fast in their inference speed, it is easy to deploy them and create customized interaction experiences. This is our next step, and we invite you to join!


